
OPENSORTS.AI (2024)
- Building a web app that allows users to explore sports statistics in natural language via a fine-tuned LLM-to-SQL engine. Designed and deployed the full-stack system on GCP with weekly data refresh pipelines, intelligent charting, and human-in-the-loop model refinement. Here is how the app works
Data Pipeline & Database
- Built weekly data pipelines that scrape ball-by-ball cricket information from multiple sources and dump it into a comprehensive database. The system contains information from every official cricket match played since 2000, providing a rich dataset for analysis.
Human-in-the-Loop Fine-tuning Process
- Step 1: Data Curation - Gave database access to “testers” to curate fine-tuning data. Since an LLM couldn’t generate accurate SQL queries purely through database schema understanding, human expertise was essential for creating high-quality training examples.
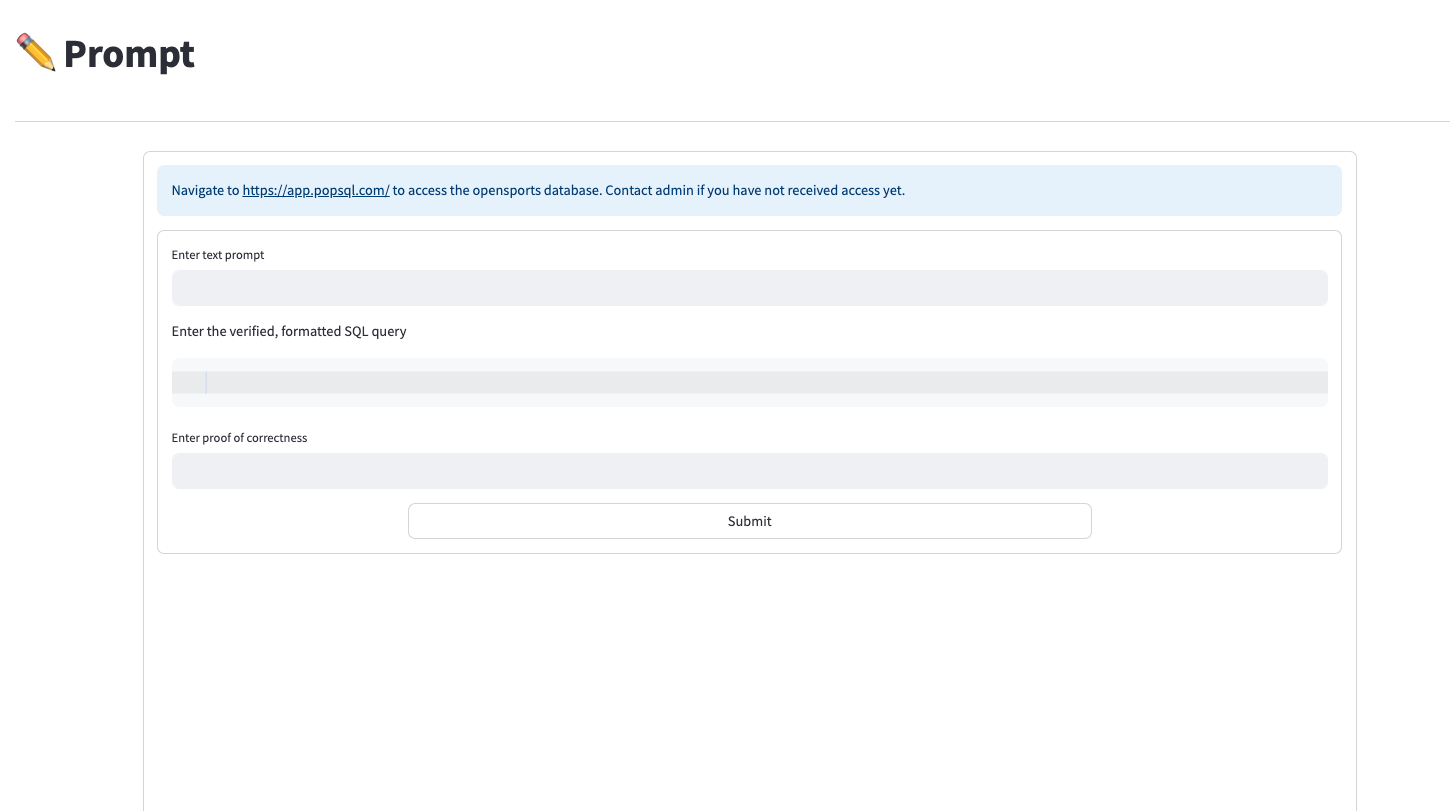
- Step 2: Verification - “Managers” had access to review the fine-tuning data created by testers. Their goal was to run the generated queries, verify correctness, and mark them as “verified” to ensure data quality.
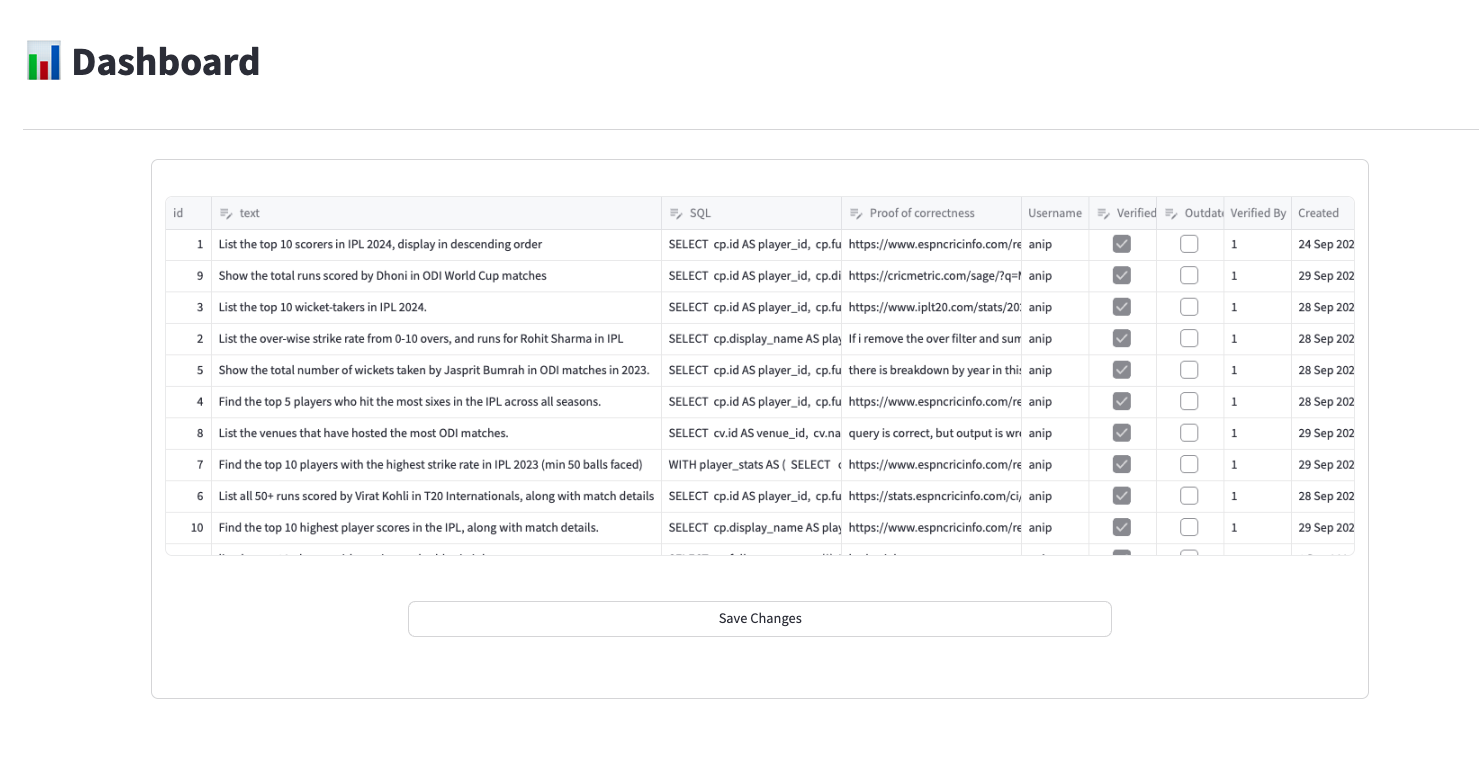
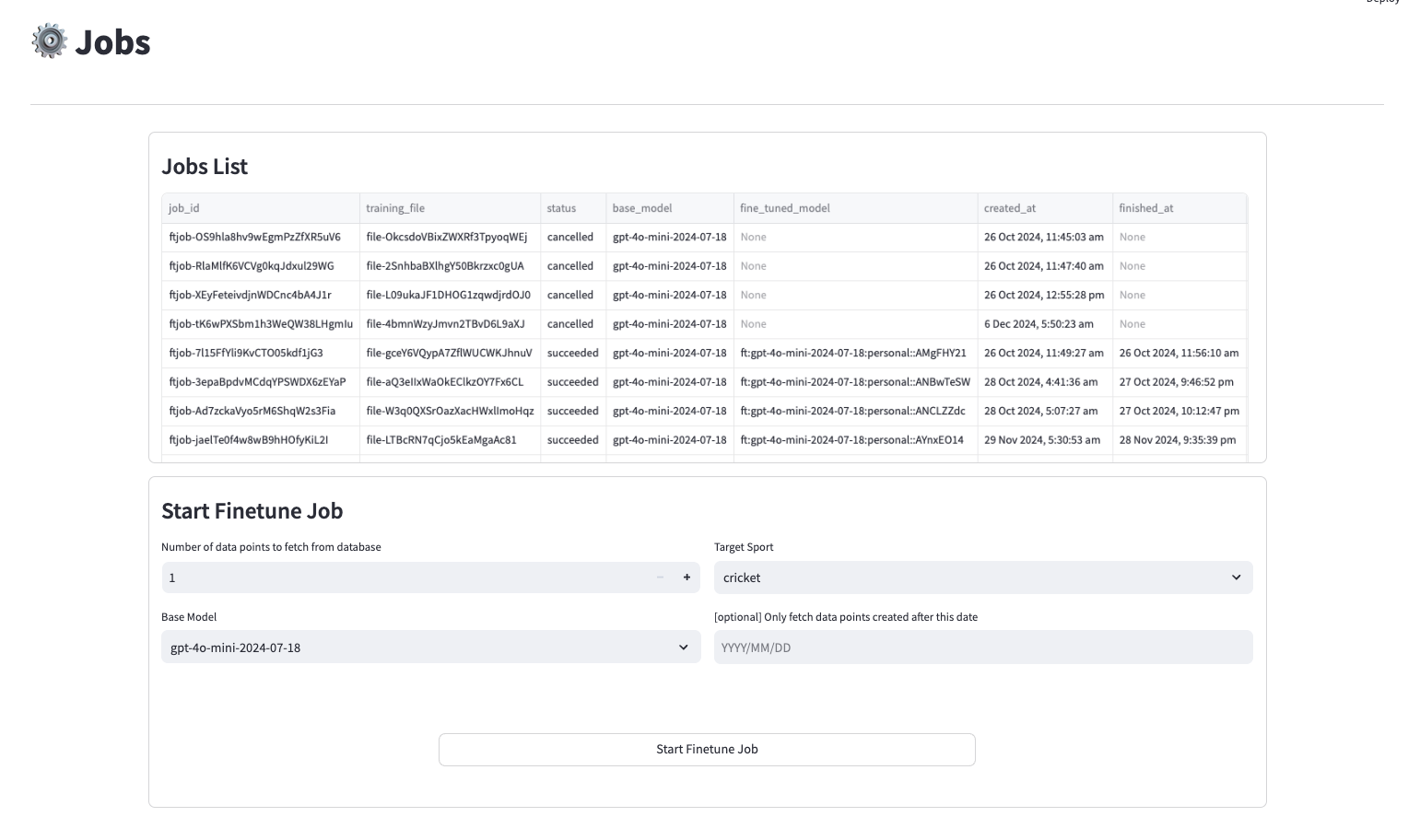
- Step 3: Model Training - Created a feedback pipeline where the latest verified fine-tuning data from testers (reviewed by managers) was used to start training jobs with OpenAI APIs, ensuring continuous model improvement.
Intelligent Query Processing & Visualization
- The fine-tuned models started performing exceptionally well for even very specific cricket insights. These models were deployed at inference time in the playground, with automated plot generation that adapts based on the type of query asked.
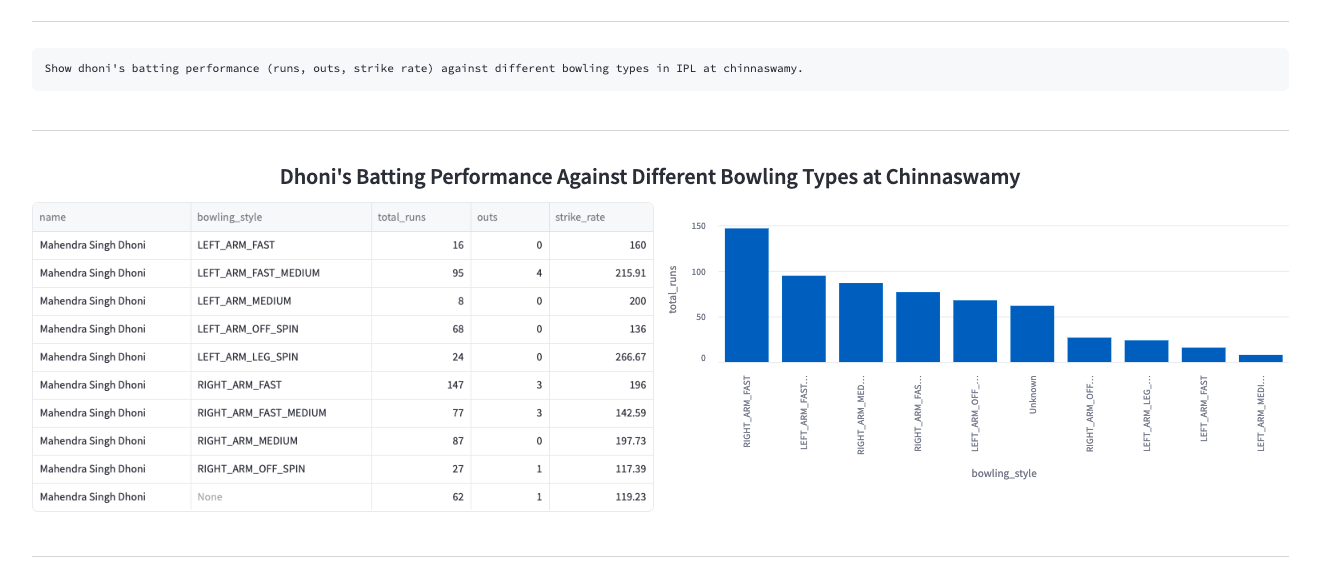
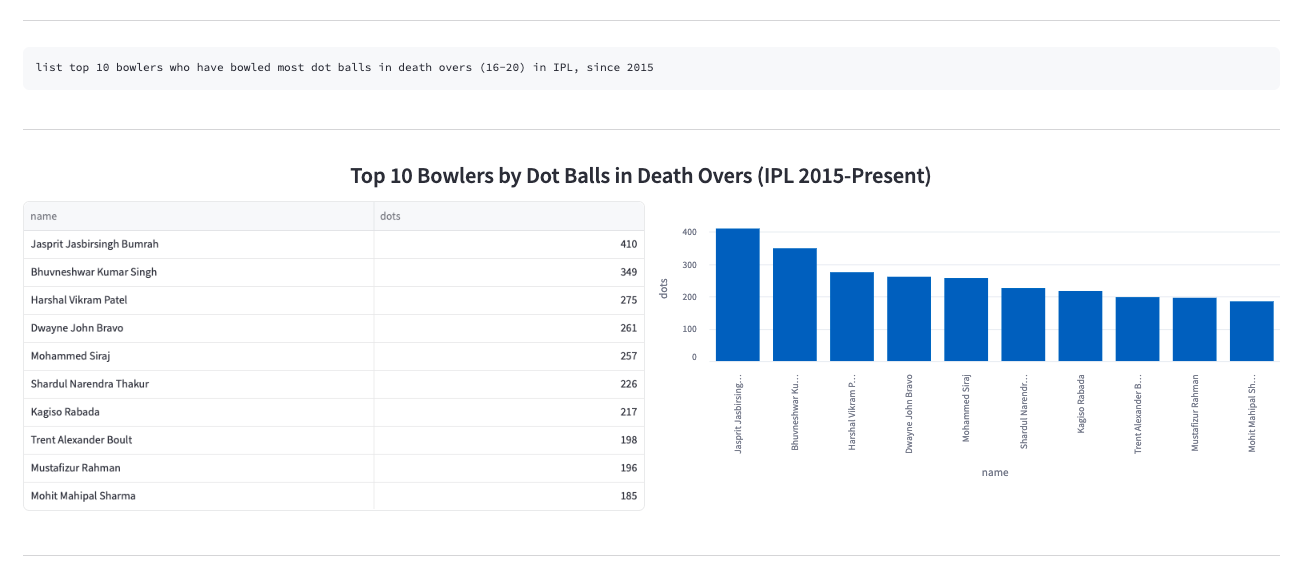
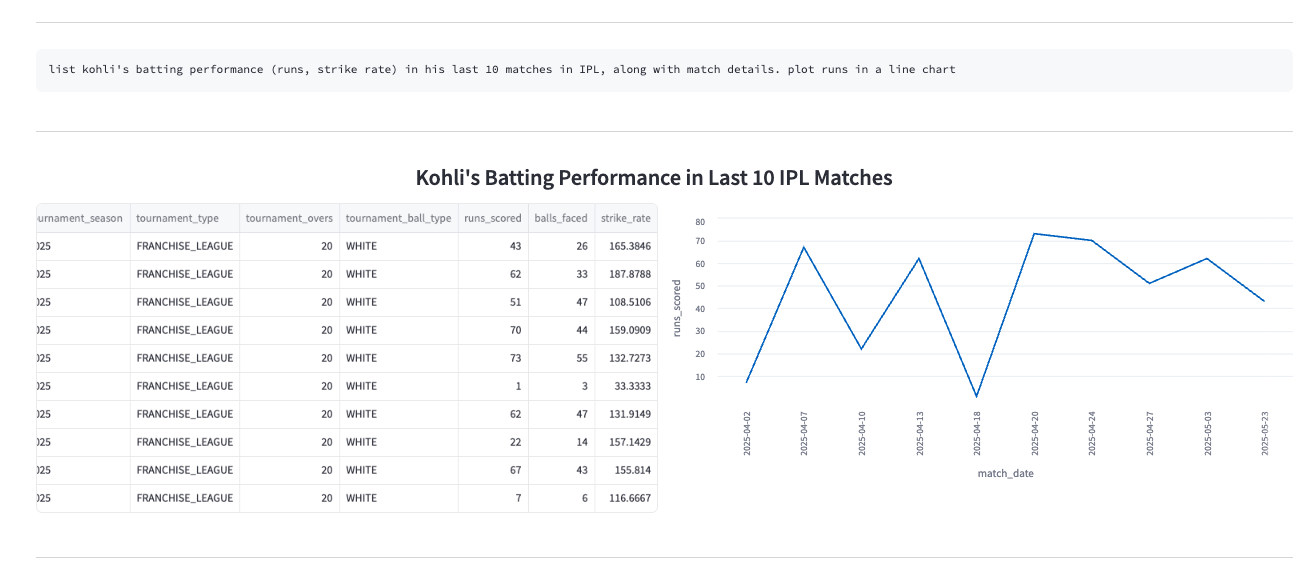
- Check out the app here. (currently down)